Introduction To Machine Learning : Walk-through of an ML Example¶
For an introduction to the terminologies of ML, as well as a brief theoretical overview, please refer to https://medium.com/@arshren/machine-learning-demystified-4b41c3a55c99¶
We look at the Iris dataset to get familiar with the tools used for ML and methodologies generally implemented to get from a dataset to the required answers.¶
Step 0: Library Imports¶
import numpy as np
NumPy is the fundamental package for scientific computing with Python. It provides efficient array objects, which are used by almost every other library in Python to handle n-dimensional arrays. It provides a very user-friendly interface, and gives a great deal of functionality.
Besides its obvious scientific uses, NumPy can also be used as an efficient multi-dimensional container of generic data. Arbitrary data-types can be defined. This allows NumPy to seamlessly and speedily integrate with a wide variety of databases.
Explore further: http://www.numpy.org/
import pandas as pd
Pandas provides high-performance, easy-to-use data structures and data analysis tools for the Python programming language. It runs NumPy in the backend, and seamlessly helps you perform tedious tasks with 1 line of code.
Explore further: https://pandas.pydata.org/
import matplotlib.pyplot as plt
%matplotlib inline
Matplotlib is a Python 2D plotting library which produces publication quality figures in a variety of hardcopy formats and interactive environments across platforms. Matplotlib tries to make easy things easy and hard things possible. You can generate plots, histograms, power spectra, bar charts, errorcharts, scatterplots, etc., with just a few lines of code.
The pyplot module provides a Matlab type interface.
Explore further: https://matplotlib.org/
import seaborn as sns
Seaborn is a Python data visualization library based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics. It interfaces well with Pandas.
Explore further: https://seaborn.pydata.org/
from sklearn.datasets import load_iris
Scikit Learn provides easy implementation of Machine Learning concepts as Black Boxes in Python. It has simple and efficient tools for data mining and data analysis, and is built on NumPy, SciPy, and matplotlib. For every ML algorithm, there is almost a standard interface you can use to implement the algorithm.
Explore further: http://scikit-learn.org/stable/
Step 1: Get the Data¶
iris_data = load_iris()
The Iris Dataset is a famous dataset, the data for which has been included directly in the Scikit Learn library. Let's explore it further.
print(type(iris_data))
The above type is speific to a dataset loaded from sklearn.datasets. It is essentially a dictionary.
print(iris_data.keys())
Let's look at the description
print(iris_data['DESCR'])
Number of instances is your training data size.
Number of attributes is your number of features for each example.
Class is your target variable.
print(iris_data['feature_names'])
We are given the names of each feature, but we may not be so lucky for other generic datasets. Having feature names allows interpretability of simple models.
Since this is such a famous repository, we can go the extent of finding out what these feature names actually mean. The following image summarises it all.
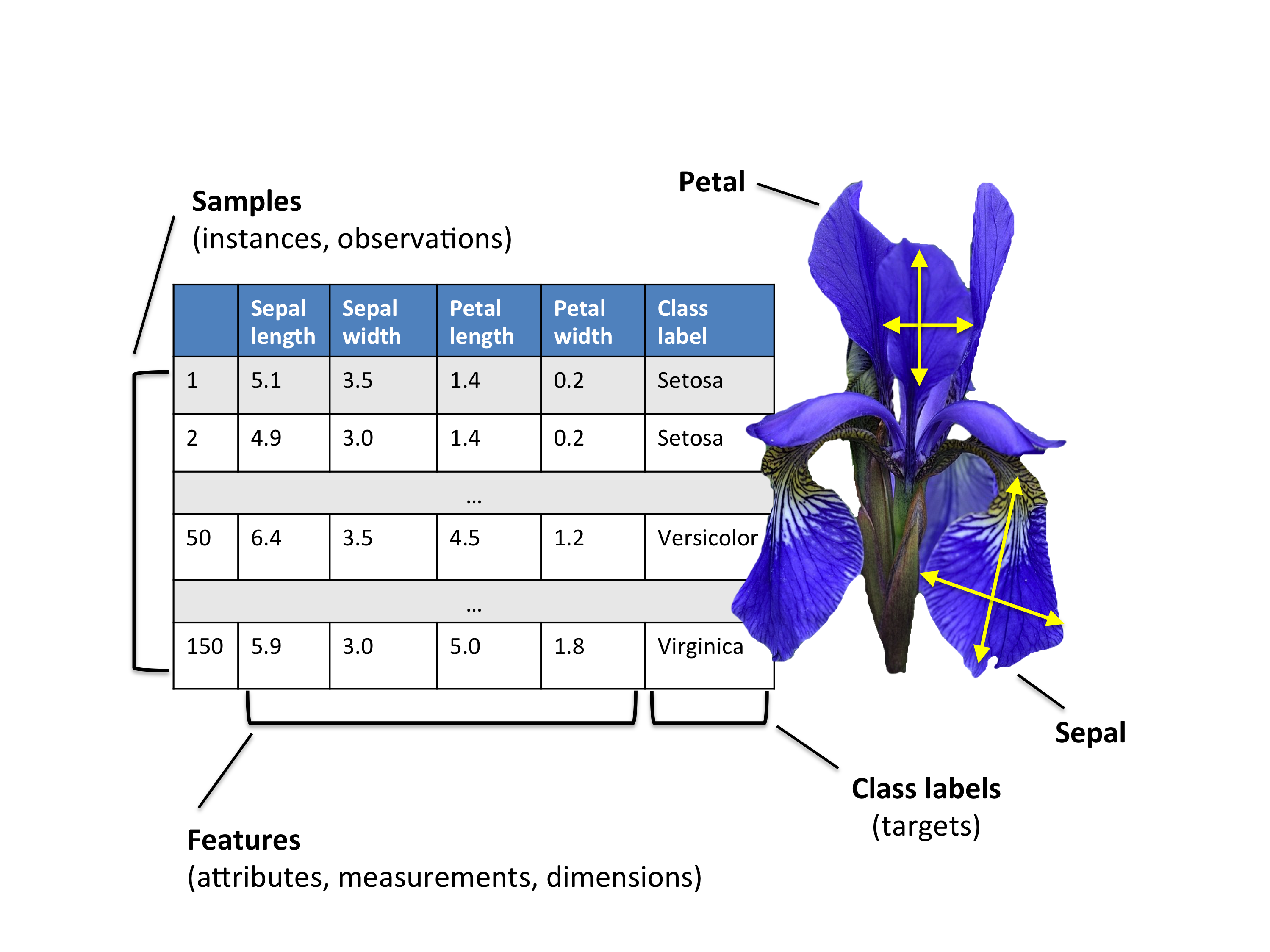
Source: https://rpubs.com/wjholst/322258
iris_dataset = pd.DataFrame(data=iris_data['data'], columns=iris_data['feature_names'])
We make a dataframe object out of the data which was in a NumPy array. Now, we can use Pandas functions to get further insights into the dataset.
iris_dataset.head()
The .head() method gives us the top few datapoint values.
iris_dataset['target'] = iris_data['target']
Inserting a new column is very simple in pandas. We can refer to the column as if it existed, and then pass in data to be stored.
iris_dataset.head()
iris_data['target_names']
These are the names for the classes:
0 - Setosa
1 - Versicolor
2 - Virginica
iris_dataset['target_name'] = np.apply_along_axis(lambda x: iris_data['target_names'][x], 0, iris_data['target'])
NumPy has an 'apply along axis' function, using which you can apply a function along a particular axis of a given array.
iris_dataset.tail()
Why convert an array to a dataframe?
Because now we can perform what is known as Exploratory Data Analysis, using only a few lines of code. Or use Pandas and Seaborn for what they're good at.
iris_dataset.describe(include='all')
The describe() function provides statistics on each data-column in the dataframe. Thus, we can quickly understand our data distribution.
iris_dataset.info()
The info() function tells us the number of non-null values in each column, alongwith the datatype of each column.
iris_dataset.corr()
The .corr() function directly tells us the correlation between each pair of columns.
sns.set_style('whitegrid')
sns.heatmap(iris_dataset.corr(), annot=True)

A heatmap is a much better way to visualize the correlations, especially for a small dataset.
sns.pairplot(iris_dataset, hue='target')

A pairplot conviniently allows us to look at the data in a pictorical format.
A scatterplot is plotted for every pair of 2 different columns.
For the same column pair, a histogram is plotted.
plt.figure(figsize=(10,6))
sns.violinplot(x = 'target', y='petal length (cm)', data=iris_dataset)

A violinplot allows us to look at kernel density estimations of data.
More: https://seaborn.pydata.org/generated/seaborn.violinplot.html
In statistics, kernel density estimation (KDE) is a non-parametric way to estimate the probability density function of a random variable. KDE gives a visual representation of the data.
More: https://en.wikipedia.org/wiki/Kernel_density_estimation
plt.figure(figsize=(10,6))
sns.barplot(x = 'target', y='petal width (cm)', data=iris_dataset)

plt.figure(figsize=(10,6))
sns.boxplot(x = 'target', y='sepal width (cm)', data=iris_dataset)

plt.figure(figsize=(10,6))
sns.kdeplot(iris_dataset['sepal length (cm)'], iris_dataset['target'])

Step 2: Preprocess the Data¶
In this dataset, we see that there are no missing values. So, we can skip that step. Instead, a lot of Linear algorithms suffer if all features are not at the same scale. Hence, we use normalization/scaling to bring all variables to the same scale.
from sklearn.preprocessing import MinMaxScaler, StandardScaler
MinMaxScaler scales the values using the minimum and maximum values of the data, to a given range provided by the user.
StandardScaler scales the data to have zero mean and unit variance.
X = iris_dataset.drop(['target', 'target_name'], axis=1)
Y = iris_dataset['target']
scaler = StandardScaler()
X_sc = scaler.fit_transform(X)
The fit method uses the data to get a few variables it needs for future use, and the transform method applies the transformation to the given input data.
fit_transform performs both in one function call.
print("Minimum:",X_sc.min())
print("Maximum:",X_sc.max())
print("Mean:",X_sc.mean())
print("Standard Devaition:",X_sc.std())
from sklearn.model_selection import train_test_split
train_test_split performs a split of the data into training and test sets.
A brief aside: Training, Test and Validation Splits:¶
For machine learning, we care about the model generalizing to unseen data. That's what makes ML a particularly interesting field. To measure performance on unseen data, we literally divide the data we have into a training set and a test set. The training data is used to train the algorithm. The test set has labels, so we can compare the output of our algorithm to these labels to find out how well it did on unseen data.
Now, one thing we need to remember is that we have multiple choices for our algorithms. And for each algorithm, we have multiple parameters that we need to set manually. So, if we use test set performance to make these choices, we may end up choosing an algorithm that will do well only on the test set, without explicitly training on it.
A workaround for this is to have another subdivision of the training set into a validation set. This set can be used to make algorithmic choices, and we will have an unbiased estimate of the performance of the final chosen algorithm using the test set.
One thing we need to consider is that the dataset we have may not be a true representative of the data on which this algorithm will finally be used. So, even though we have an explicit test set, real performance may differ.
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25, shuffle=True)
We do not need scaling of the variables in this example, so we apply train-test-split to the original data.
Is it practical to split the data, if we have very little of it (like for this example), have into even smaller sections?
Here, we use a concept of K-fold cross-validation. The training data is split into K equal subsets, and we train the algorithm K times, each time using a diferent subset of the data as the validation set. Thus, we get a somewhat good estimate of the validation accuracy to find the best model.
Step 3: Use an ML Algorithm to predict the class¶
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neural_network import MLPClassifier
For any ML algorithm in Scikit Learn, we have a fit and score method.
We always first create an object of the class of the algorithm, and provide parameters to it during the creation of the object.
Next, we call the .fit() method to train the algorithm on the data we provide as arguments to this function.
Finally, we can call .score() to get the score of the algorithm.
lr = LogisticRegression()
lr.fit(X_train, Y_train)
print(lr.score(X_train, Y_train))
print(lr.score(X_test, Y_test))
from sklearn.model_selection import cross_val_score
cross_val_score will run cross_validation on given model, and return an array of scores on the validation set.
cv = cross_val_score(lr, X, Y, cv=5)
print(cv)
print(cv.mean())
dtc = DecisionTreeClassifier()
dtc.fit(X_train, Y_train)
print(dtc.score(X_train, Y_train))
print(dtc.score(X_test, Y_test))
cv = cross_val_score(dtc, X, Y, cv=5)
print(cv)
print(cv.mean())
mlp = MLPClassifier(hidden_layer_sizes=(10,10), max_iter=3000)
mlp.fit(X_train, Y_train)
print(mlp.score(X_train, Y_train))
print(mlp.score(X_test, Y_test))
cv = cross_val_score(mlp, X, Y, cv=5)
print(cv)
print(cv.mean())
All the above algorithms have their individual hyperparameters that need tuning. Hyperparameters are basically parameters of the algorithm that we have to set.
Future blog posts will explore ML algorithms in depth, alongwith their implementation from scratch (using minimal libraries).
A brief overview will be given before diving into depth, so please do check them out!
Thanks for reading! Please do feel free to connect with us on LinkedIn, and leave feedback for us on Twitter.
LinkedIn: https://www.linkedin.com/in/aditya-khandelwal/
https://www.linkedin.com/in/renu-khandelwal/
Twitter: https://twitter.com/adityak6798